记录集
8.0 新版功能: 本文档的新API应该作为odoo8.0以后主要的API。它还提供了有关移植或桥接7.0和 更早版本的“旧API”的信息,但该API没有明确地文档。看到旧的文档。
通过同一模块排序的记录集将模块和记录的相互作用表现出来。
警告
相反,顾名思义,目前可能记录集里包含重复。这可能会在未来改变。
在一个记录集上执行模块上定义的方法,并且 self 是一个记录集:
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self can be anywhere between 0 records and all records in the
# database
self.do_operation()
迭代一个记录集将产生新的 一个单独记录 的集合("singletons"),就像一个Python字符串迭代 生成一个单一字符串:
def do_operation(self):
print self # => a.model(1, 2, 3, 4, 5)
for record in self:
print record # => a.model(1), then a.model(2), then a.model(3), ...
字段访问
记录集提供一个“激活记录”界面: 模块字段可以通过这个记录直接被读和写,但是仅限单一记录集(signle-record)。 设置一个字段的值将触发一次数据库更新:
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
尝试在多个记录中读取或写入字段会激发一个错误。
访问一个关联字段(Many2one,
One2many, Many2many) 总是 返回一个记录集,
如果该字段没有值将返回空的记录集。
危险
每次赋值给一个字段将触发一次数据库更新, 当同一时间设置多个字段或给多个记录
设置字段(赋相同的值), 使用 write():
# 3 * len(records) database updates
for record in records:
record.a = 1
record.b = 2
record.c = 3
# len(records) database updates
for record in records:
record.write({'a': 1, 'b': 2, 'c': 3})
# 1 database update
records.write({'a': 1, 'b': 2, 'c': 3})
记录缓存和预取
Odoo为记录中的字段维持一个缓存空间,因此不是每次访问字段都触发数据库请求, 不然那将对性能的影响是可怕的。这个下面例子只对第一个语句进行数据库查询:
record.name # first access reads value from database
record.name # second access gets value from cache
为了避免每次读一个记录上的一个字段,Odoo 预取 记录和字段借鉴一个启发式算法以获得更好的性能。 一旦一个字段必须在给定的记录上被读取,这个ORM实际在一个大的记录集上读取该字段,并且以便下一个 用户读取,将该字段返回的值到存储到缓存中,所有基础存储的字段(boolean, integer, float, char, text, date, datetime, selection, many2one)被同时获取到;它们对应于模型表的列,并在同一 查询中高效地获取。
考虑下面这个例子, partners 是一个有1000条记录的记录集。如果没有预取,该循环将对数据库
进行2000次查询,如果有预取,仅仅需要查询一次:
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
预取也适用于 二次记录 :当关系字段被读取时,它们的值(这是记录)为将来的预取订阅。其中访问二次 记录中的某个字段只需从相同的模型预取所有次要记录。这使得下面的示例只生成两次查询, 一个用于合作伙伴,另一个用于国家:
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
集合操作
记录集是不变的,但是相同模块的集合可以通过使用一系列的操作符来结合,返回新的记录集, 集合操作 不 保留顺序
record in set是否返回record(第一项必须是一个元素的记录集) 在set中 。record not in set是相反的操作set1 <= set2和set1 < set2返回是否set1是set2的子集set1 >= set2和set1 > set2返回是否set1是set2的超级set1 | set2返回两个集合的合集,一个新的记录集包括任一个集合中的所有记录set1 & set2返回两个集合的并集,一个新的记录集仅包括两个集合中都有的记录set1 - set2返回一个记录在set1而不set2中的新的记录集
其他记录集操作方法
记录集是可迭代的因此通常的Python 工具是可用于转化的(map(), sorted(),
ifilter(), ...) 然而这些返回的要么是 list
要么是 iterator ,去除了在结果之上调用的方法的能力,或者去除了使用集合的操作。
记录集因此提供这些操作返回记录集本身:
filtered()返回一个只包含满足提供判定函数的记录集。判定也可以是由真或假字段筛选的字符串:
# only keep records whose company is the current user's records.filtered(lambda r: r.company_id == user.company_id) # only keep records whose partner is a company records.filtered("partner_id.is_company")
sorted()返回一个通过关键字函数排序的记录集。如果未提供关键字,使用模块默认的排序:
# sort records by name records.sorted(key=lambda r: r.name)
mapped()将提供的函数应用于记录集中的每一条记录,如果结果是记录集将返回一个记录集:
# returns a list of summing two fields for each record in the set records.mapped(lambda r: r.field1 + r.field2)
提供的函数可以使字符串来获取字段的值:
# returns a list of names records.mapped('name') # returns a recordset of partners record.mapped('partner_id') # returns the union of all partner banks, with duplicates removed record.mapped('partner_id.bank_ids')
环境
Environment通过ORM存储各种环境中的数据:数据库游标(数据库查询) 、- 当前用户 (用来权限检查)、当前环境(存储任意的元数据)。环境可以被存储在缓存中。
所有的记录集都有一个不可变的环境,它可以通过 env 访问,通过
(user), 游标
(cr) or 上下文
(context)给当前用户访问:
>>> records.env
<Environment object ...>
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...)
当从其他记录集创建了一个记录集,这个环境是可以被继承的。环境可以被用于从其他模块获取一个空的记录集, 并且查询这个模块:
>>> self.env['res.partner']
res.partner
>>> self.env['res.partner'].search([['is_company', '=', True], ['customer', '=', True]])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
转换环境
来自一个记录集的环境可以被定制。使用转换环境返回一个新版本的记录集。
sudo()根据提供的用户来创建一个新的环境,如果没有提供则使用管理员(绕过权限/规则的安全上下文), 返回一个调用使用新的环境的记录集:
# create partner object as administrator env['res.partner'].sudo().create({'name': "A Partner"}) # list partners visible by the "public" user public = env.ref('base.public_user') env['res.partner'].sudo(public).search([])
with_context()- 可以携带一个位置参数,它将取代目前的环境的上下文
可以通过关键字携带任意数量的参数,这些参数将被增加到当前环境上下文中或步骤1中的上下文设置中:
# look for partner, or create one with specified timezone if none is # found env['res.partner'].with_context(tz=a_tz).find_or_create(email_address)
with_env()- 彻底替换现存的环境
共用的ORM方法
search()
提供一个 search domain ,返回一个匹配的记录集。
也可以返回匹配的记录集的子集,通过 offset 和 limit 参数,同时通过 order 参数排序:
>>> # searches the current model
>>> self.search([('is_company', '=', True), ('customer', '=', True)])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
>>> self.search([('is_company', '=', True)], limit=1).name
'Agrolait'
.. tip:: 只检查是否有任何匹配的记录,或计数的数目,使用 :meth:`~odoo.models.Model.search_count`
create()提供一系列数量字段的值,返回包含该记录的记录集:
>>> self.create({'name': "New Name"}) res.partner(78)
write()提供一系列字段值,将他们写入到记录集中的所有记录中。不返回任何东西:
self.write({'name': "Newer Name"})
browse()提供数据库id或者ids的集合,返回一个记录集,当记录的id从odoo之外被获取是有用的 (例如 往返通过外部的系统)或:ref:[UNKNOWN NODE title_reference]:
>>> self.browse([7, 18, 12]) res.partner(7, 18, 12)
exists()返回一个仅存在于数据库中记录的新的记录集。可以用来检查是否该记录依旧存在:
if not record.exists(): raise Exception("The record has been deleted")
或者调用一个方法后应该移除一些记录:
records.may_remove_some() # only keep records which were not deleted records = records.exists()
ref()环境的方法返回匹配到的 external id 的记录:
>>> env.ref('base.group_public') res.groups(2)
ensure_one()检查该记录集是一个signleton(仅包含一个单一记录),否则提示一个错误:
records.ensure_one() # is equivalent to but clearer than: assert len(records) == 1, "Expected singleton"
创建模块
模块字段作为属性被定义在模块上:
from odoo import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
警告
意思你不能用同一个名字定义一个字段和方法,它们会冲突
默认字段标签(用户可见的名字)是该字段首字母大写的名字,它可以被 string 属性复写:
field2 = fields.Integer(string="an other field")
针对不同类型字段和参数,看 参考该字段
默认值作为参数被定义在字段上,要么是一个值:
a_field = fields.Char(default="a value")
要么是一个被调用来计算默认值的函数,该函数应该返回那个值:
def compute_default_value(self):
return self.get_value()
a_field = fields.Char(default=compute_default_value)
计算字段
字段可以被计算(而不是直接从数据库读出来)使用 compute 参数。 它必须将计算的值赋值给该字段 。
如果它使用其他 字段 的值,它应该指明这些字段使用 depends():
from odoo import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
当使用子字段时可以使用点操作:
@api.depends('line_ids.value') def _compute_total(self): for record in self: record.total = sum(line.value for line in record.line_ids)
- 计算字段默认不被存储,当请求时它们被计算和返回。设置
store=True将被存储在数据库中 并可以自动被搜索 通过设置
search参数来在计算字段上搜索。该值是一个方法的名字返回一个 Domain:upper_name = field.Char(compute='_compute_upper', search='_search_upper') def _search_upper(self, operator, value): if operator == 'like': operator = 'ilike' return [('name', operator, value)]
允许 设置 值到计算字段,使用
inverse参数。它是一个函数的名称反转计算并且设置关联字段:document = fields.Char(compute='_get_document', inverse='_set_document') def _get_document(self): for record in self: with open(record.get_document_path) as f: record.document = f.read() def _set_document(self): for record in self: if not record.document: continue with open(record.get_document_path()) as f: f.write(record.document)
多个字段可以在同一时间通过同一方法被计算出来, 仅仅使用相同的方法在所有的字段上 并且设置它们:
discount_value = fields.Float(compute='_apply_discount') total = fields.Float(compute='_apply_discount') @depends('value', 'discount') def _apply_discount(self): for record in self: # compute actual discount from discount percentage discount = record.value * record.discount record.discount_value = discount record.total = record.value - discount
关联字段
一个特殊的计算字段是 related (代理)字段,该字段在当前记录提供一个子字段的值.
他们通过 related 参数被指定并且像常规的计算字段可以被存储:
nickname = fields.Char(related='user_id.partner_id.name', store=True)
onchange: 运行中更新界面
当一个用户在表单视图改变一个字段值(但是还没保存),它可以基于这个值被用于自动更新其他字段 例如,当税收改变或者添加一个新的发票行将更新最终总数。
- 计算字段会自动检查并重新计算,他们不需要onchange
对于非计算字段,这个onchange()装饰器被用于提供新字段:
@api.onchange('field1', 'field2') # if these fields are changed, call method def check_change(self): if self.field1 < self.field2: self.field3 = True
在这个方法被发送至客户端程序并且对用户可视时,这个改变被展现出来
- 计算字段和新的onchanges API通过客户端被自动调用无需添加他们在视图中
通过添加on_change="0” 在view中来抑制一个指定字段触发onchange方法:
<field name="name" on_change="0"/>
当该字段被用户编辑时,将不会触发任何界面更新,即使这有个函数字段或明确的onchange依赖于该字段
注解
onchange 方法运行在虚拟记录赋值这些记录是不写入数据库,只是用来知道这值返回给客户
底层SQL
cr环境属性是针对当前事务的游标和允许直接执行SQL,要么是难以使用ORM来进行表达, 要么是性能的原因:
self.env.cr.execute("some_sql", param1, param2, param3)
由于模块使用相同的游标并且 Environment 保存不同的缓存,当在原生的SQL中 变更
数据库时这些缓存必须失效,或者进一步利用模块来变成不相干。当在SQL中使用 CREATE, UPDATE 或者 DELETE
时必须清除缓存, 在 SELECT 中则不需要(这只是简单的读取数据库)。
清除缓存可以使用 Environment 对象中的
invalidate_all() 方法。
新旧API的兼容性
Odoo目前正从旧的API中过渡,手动通旧API建立桥梁是必须的:
- RPC 层(XML-RPC和JSON-RPC)是用旧的API来表示的,单纯使用新的API表达式方法是不可用RPC的
- 从旧系列的代码重写被调用的方法仍然需要使用旧API的风格
新旧API之间最大的不同:
Environment(游标,用户id和上下文)的值直接通过方法传递- 记录数据(
ids)通过明确的方法传递,而且根本没有通过 - 方法趋向使用列表而不是记录集
默认情况下,方法假定使用新API风格而不是调用旧的API。
小技巧
从新到旧API的调用是桥接的
当使用新的API风格,使用旧的API定义的方法被调用时在运行中将自动转换,不需要做任何指定:
>>> # method in the old API style
>>> def old_method(self, cr, uid, ids, context=None):
... print ids
>>> # method in the new API style
>>> def new_method(self):
... # system automatically infers how to call the old-style
... # method from the new-style method
... self.old_method()
>>> env[model].browse([1, 2, 3, 4]).new_method()
[1, 2, 3, 4]
两个装饰器可以使新风格的方法运用到旧的API中:
model()该方法没有使用ids被展现出来,它的记录集是空的,对应旧的API的
cr, uid, *arguments, context:@api.model def some_method(self, a_value): pass # can be called as old_style_model.some_method(cr, uid, a_value, context=context)
multi()该方法携带一系列ids被展现出来,对应旧的API的
cr, uid, ids, *arguments, context:@api.multi def some_method(self, a_value): pass # can be called as old_style_model.some_method(cr, uid, [id1, id2], a_value, context=context)
由于新风格的APIs趋向返回记录集而旧的APIs趋向返回一系列id的列表,因此这也有管理这个的装饰器:
returns()该函数被假定返回一个记录集,第一个参数应该被命名为记录集的模块或者
self(针对当前模块)如果该方法在新的API风格中被调用时没有作用的,但是当调用旧的API风格时将记录集转换为一系列id的列表:
>>> @api.multi ... @api.returns('self') ... def some_method(self): ... return self >>> new_style_model = env['a.model'].browse(1, 2, 3) >>> new_style_model.some_method() a.model(1, 2, 3) >>> old_style_model = pool['a.model'] >>> old_style_model.some_method(cr, uid, [1, 2, 3], context=context) [1, 2, 3]
模块参考
装饰器方法
字段
基础字段
关联字段
继承和扩展
Odoo提供三种不同以模块化方式扩展模型:
- 从现有模型创建新模型,向副本添加新信息,但保留原始模模型
- 扩展其他模块中定义的模型,替换以前的版本
- 将一些模型的字段委托给它包含的记录
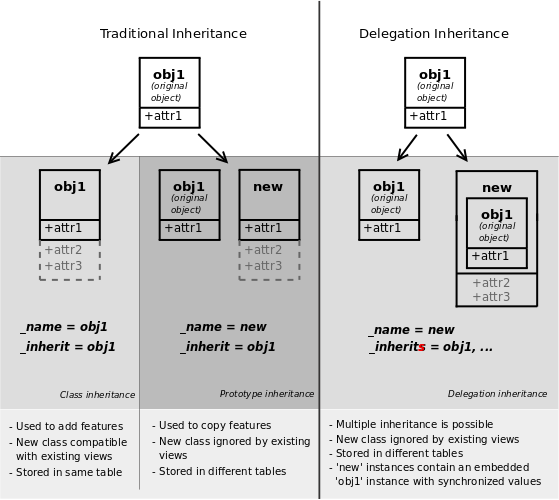
原型继承
当同时使用 _inherit 和 _name
属性时, Odoo使用现有的模型作为基础来创建一个新的模型(通过提供 _inherit )。
这个新的模型从基础模型中获取所有的字段,方法和元信息(默认值和al)
并且使用它们:
将会yield:
第二个模型继承了第一个模型的 check 方法和 name 字段,但是覆盖了 call 方法,因为当使用标准 Python inheritance 。
扩展继承
当使用 _inherit 但是没有提供 _name 时,
新模型替代已存在的模型,本质是在原有模型进行扩展。对于添加新字段或方法是非常有用的,或者去定制或重新配置它们
(例如 改变它们的默认排序):
将会yield:
注解
它也将产生各种 automatic fields 除非它们已被禁用
委托继承
第三种继承机制提供了更多的灵活性(可以改变在运行时)但有较少的功能:
使用 _inherits 模型*委托*查找当前模型中未找到的任何字段
到“儿童”模型。委托通过以下方式执行 Reference 字段在父代上自动设置
模型:
将导致:
并且可以直接在委托字段上写入:
警告
当使用委托继承时,方法不被继承,只继承字段
Domain
domain是一个标准列表,每个标准是一个三元组(要么是 list 或是一个 tuple )的
(field_name, operator, value) :
field_name(str)- 当前模型的字段名,或者通过
Many2one的关系遍历, 使用点符号。'street'或partner_id.country' operator(str)用于比较
field_name和value的操作符。有效的操作符有:=- 相等
!=- 不等
>- 大于
>=- 不小于
<- 小于
<=- 不大于
=?- 未设置或等于(如果
value为None或False,则返回真,否则表现为=) =like- 匹配
field_name与value模式。 模式中的下划线 “_” 代表任何单个字符(匹配) 百分号“%”匹配任何零个或多个字符的字符串。 like- 匹配
field_name与value模式。类似于= like,但在匹配之前用“%”包装value not like- 不匹配
%value%的模式 ilike- 等同于不区分大小写的
like not ilike- 等同于不区分大小写的
not like =ilike- 等同于不区分大小写的
=like in- 等于
value中的任意一项,value应该是一个列表 not in- 不等于
value中的任意一项 child_of是一个
value记录的子节点(子孙)采用模型的语义(即关系字段命名为
_parent_name)。
value- 变量类型,必须是与命名字段可比的(通过
operator)
可以使用 prefix 形式的逻辑运算符组合Domain条件
'&'- 逻辑运算符 AND ,组合条件的默认操作。 Arity 2(使用接下来的两个标准或组合)。
'|'- 逻辑运算符 OR, arity 2.
'!'逻辑运算符 NOT, arity 1.
小技巧
主要是否定标准的组合 :class: aphorism
个别标准通常有一个否定形式(例如
=->!=,<->>=)比简单的否定更有效
Example
要搜索来自比利时或德国且语言不是英语且名为 ABC 的合作伙伴:
[('name','=','ABC'),
('language.code','!=','en_US'),
'|',('country_id.code','=','be'),
('country_id.code','=','de')]
该domain解释为:
(name is 'ABC')
AND (language is NOT english)
AND (country is Belgium OR Germany)
从旧API移植到新API
- 在新API中要避免使用ids的裸列表,使用记录集替代
- 仍然写在旧API中的方法应该自动桥接ORM,不需要切换到旧的API,只需调用它们就像是一个新的API方法。 有关更多详细信息,请参见 自动桥接旧API方法 。
search()返回一个记录集。- 通过常规的字段类型
related=或compute=参数来替换fields.related和fields.function depends()在compute =方法上 必须是存在的 , 它必须列出 所有 计算方法使用的字段和子字段。太多的依赖(在不需要的情况下重新计算字段)比不够(将忘记重新计算字段,然后值将不正确)好- 在计算字段上移除 所有
onchange方法。当它的依赖字段改变时计算字段会自动重新计算,并且用于由客户端自动生成onchange - 装饰器
multi()用于桥接 当从旧的API上下文 调用时,对于内部或新的api(例如 计算)是无用的 - 移除
_default, 在对应字段上用default=替代 如果一个字段的
string =是字段名的首字母大写的版本:name = fields.Char(string="Name")
那是没有什么作用的,应该被移除
multi =参数在新的API字段上不做任何事情,使用相同的compute =方法在所有相关字段上得到相同结果- 通过名称(一个字符串)提供
compute =,inverse =和search =方法,这使得它们可以重写(不需要中间“跳转”函数) - 双重检查所有字段和方法有不同的名称,在碰撞情况下没有警告(因为Python在Odoo看到任何东西之前处理它)
- 正常的新api导入是
from odoo import fields,models。 如果兼容性装饰器是必要的,使用from odoo import api,fields,models - 避免使用
one()装饰器, 它有可能执行你不期望的事 - 删除显示定义的
create_uid,create_date,write_uid和write_date字段: 它们现在被创建为常规的“合法”字段,并且可以 像任何其他字段一样读写 当不可能进行直接转换(语义不能被桥接)或“旧API”版本是不可取的并且可以针对新的API进行改进时, 可以使用完全不同的“旧API”和“新API”实现相同的方法名使用
v7()和v8()。 该方法应该首先使用old-API风格定义,并装饰v7(),然后应该使用完全相同的名称重新定义, 但新的API风格和装饰v8()。 来自旧API上下文的调用将被分派到首要实现, 并且来自新API上下文的调用将被分派到次要实现。 一个实现可以通过切换上下文来调用(并且频繁地)调用另一个实现。危险
使用这些装饰器使方法非常难以覆盖和更难以理解和记录
_columns或_all_columns应该被_fields所替代, 它提供通过新风格odoo.fields.Field对实例进行访问(而不是旧风格odoo.osv.fields._column)使用新的API样式创建的非存储计算字段是 不 可用于
_columns, 只能通过以下方式检查_fields- 在方法中重新分配
self是非必需的并且有可能破坏翻译自省 Environment对象依赖于一些threadlocal状态,在使用它们之前必须设置它们。有必要使用odoo.api.Environment.manage()上下文管理器尝试在尚未设置的新环境中使用新API,例如新线程或Python交互式环境:
>>> from odoo import api, modules >>> r = modules.registry.RegistryManager.get('test') >>> cr = r.cursor() >>> env = api.Environment(cr, 1, {}) Traceback (most recent call last): ... AttributeError: environments >>> with api.Environment.manage(): ... env = api.Environment(cr, 1, {}) ... print env['res.partner'].browse(1) ... res.partner(1,)
自动桥接旧API方法
当模型被初始化时,如果它们看起来像在旧API样式中声明的模型,则所有方法都被自动扫描和桥接。 这种桥接使得它们可以从新的API样式方法中透明地调用。
如果被调用的第二个位置参数是 cr 或 cursor ,则被匹配为旧API风格的方法。该系统也会辨别
第三个位置参数被称为 uid 或 user 和 第四个位置参数被称为 id 或 ids 。它也会辨别
任意被命名为 context 参数的存在。
当从一个新API上下文调用这样的方法时,系统会自动从当前环境 Environment
调用(cr , user 和
context) 或者当前的记录集 (for id
and ids)。
在极少数需要的情况下,桥接可以通过装饰旧式方法来定制:
- 完全禁用它,通过装饰一个方法
noguess()这将不会有桥接并且方法将以准确的方式从新和旧的API风格调用 显式地定义桥接,这主要是对于不正确匹配的方法(因为参数以意想不到的方式命名):
cr()- 将自动地将当前游标添加到显式提供的参数位置
cr_uid()- 将自动地将当前游标和用户id添加到显式提供的参数位置
cr_uid_ids()- 将自动地将当前游标、用户id和记录集的ids添加到显式提供的参数位置
cr_uid_id()- 将循环当前记录集,并为每个记录调用该方法一次,将当前游标,用户id和记录id添加到显式提供的参数位置。
危险
当从一个新的API上下文调用时,这个包装器的结果是 总是一个列表 所有这些方法都有一个
_context后缀版本(例如cr_uid_context()),它也通过关键字 传递当前上下文 。- 双重实现使用
v7()和v8()将被忽略,因为他们提供自己的“桥接”